Pre-trained language models encode rich linguistic features—probing classifiers can decode syntax, semantics, and more with high accuracy. Yet when these same models are fine-tuned for downstream tasks, they often rely on spurious heuristics instead. Why would a model prefer a weak feature over a stronger one, if both are extractable from its representations?
We test a simple hypothesis: a model's use of a feature can be predicted from two factors—the feature's extractability after pre-training (how easily it can be decoded from the representation) and the evidence available during fine-tuning (how often the feature co-occurs with the label). Our motivation comes from McCoy et al. (2019), which showed that BERT fine-tuned on NLI relies on lexical overlap heuristics despite having access to richer syntactic features.
The core finding: the more extractable a target feature is relative to a competing spurious feature, the less statistical evidence the model needs during fine-tuning to prefer the right feature. Probing classifiers can thus be viewed as measures of a representation's inductive biases.
Setup and terminology#
Consider a binary classification task with a target feature t that perfectly predicts the label, and a spurious feature s that is correlated with the label but not infallible. We partition examples into four regions based on which features hold:
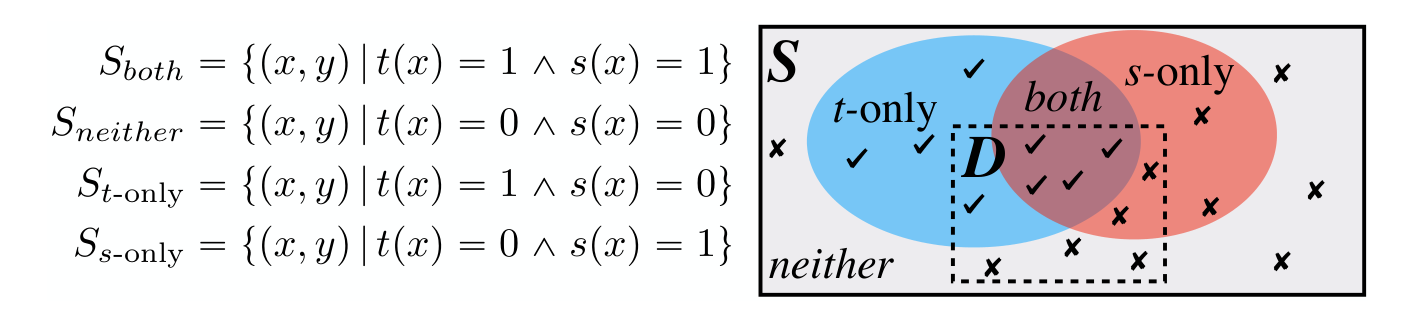
The s-only rate is the proportion of training examples where the spurious feature occurs without the target—this is the model's evidence that s alone should not be trusted. The s-only error measures how much the model still relies on the spurious feature at test time.
To quantify extractability, we use Minimum Description Length (MDL), MDL, first applied to probing by Voita & Titov (2020), measures the number of bits required to communicate feature labels given the representations. Lower MDL means the feature is easier to extract. an information-theoretic metric that captures both how accurately a feature can be decoded and how much effort is required. The key quantity is the relative extractability: MDL(s)/MDL(t). When this ratio is high, the target is easier to extract than the spurious feature.
Hypothesis: A model's use of the target feature is modulated by the relative extractability of t vs. s and the evidence from s-only examples. Higher relative extractability of t → the model needs less evidence to prefer t over s.
Synthetic experiments#
We first test the hypothesis in a clean setting using synthetic data: sequences of 10 numbers classified by a 1-layer LSTM. The spurious feature s is always the presence of the symbol 2. We vary the target feature t to achieve different levels of extractability:
| Target Feature | Description | Rel. MDL |
|---|---|---|
| contains-1 | 1 occurs in the sequence | 1.259 |
| prefix-dupl | Begins with a duplicate | 0.002 |
| adj-dupl | Adjacent duplicate in sequence | 0.001 |
| first-last | First number equals last | 0.001 |
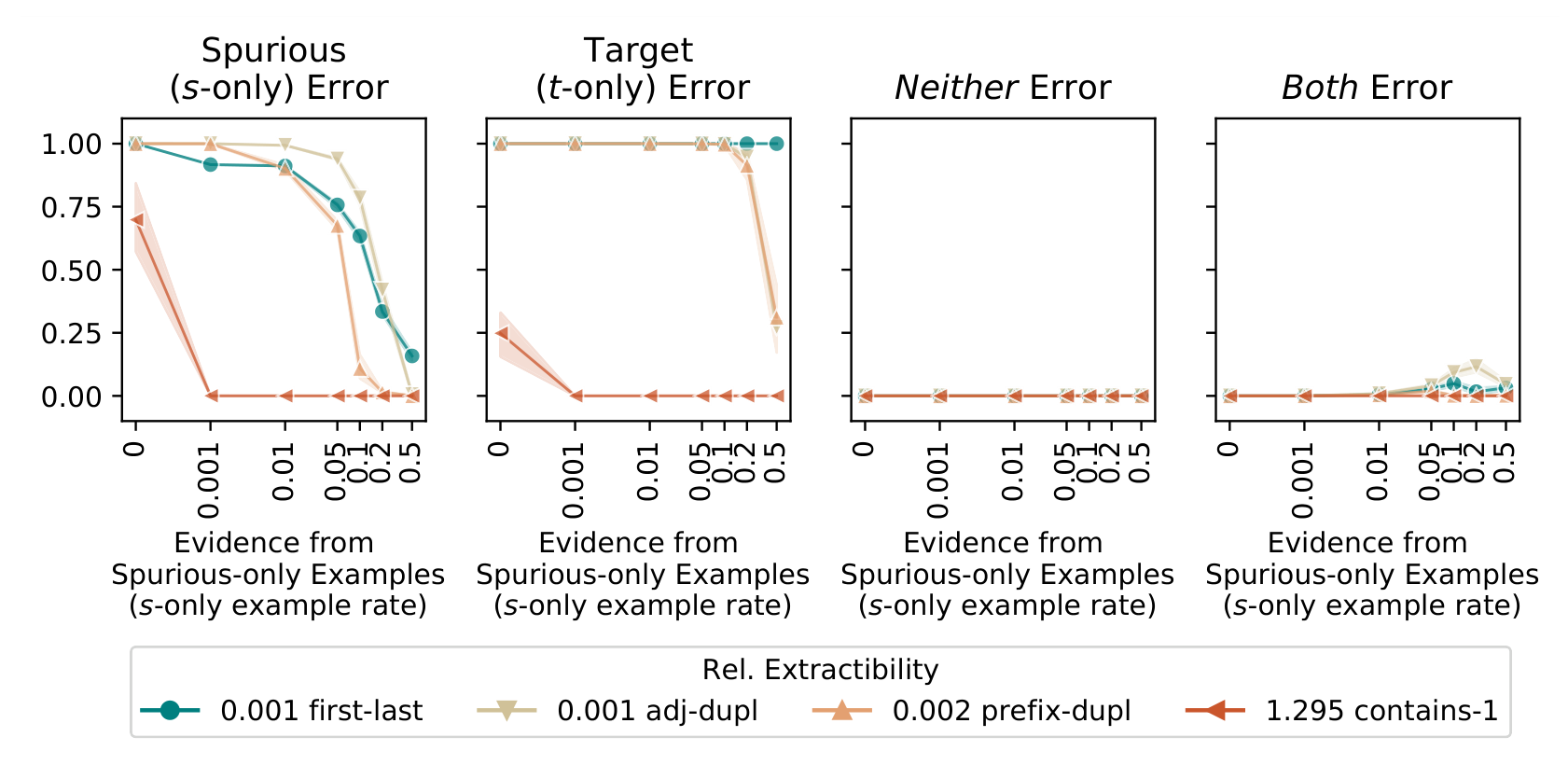
contains-1,
rel. MDL ≈ 1), the model achieves zero error with almost no evidence. When t is harder to extract (first-last),
the model fails even with strong evidence against the spurious feature.Naturalistic experiments#
We test whether the same trend holds for real language models fine-tuned on naturalistic data. We evaluate BERT, RoBERTa, T5, GPT-2, and a GloVe-LSTM on linguistic acceptability tasks across three syntactic phenomena: Subject-Verb Agreement, Negative Polarity Items, and Filler-Gap Dependencies. For each phenomenon, we introduce four types of spurious features (lexical, length, plural, tense), yielding 20 distinct (s, t) pairs across which we measure relative extractability.
| Target | Spurious | Example |
|---|---|---|
| Subject agrees with verb | Preceding noun is singular | “The piano teachers of the lawyer wound…” |
| NPI in licensing context | Contains negation word | “No student who was wrong ever resigned.” |
| Correct filler-gap | Main verb is past tense | “I knew what he recognized __ yesterday.” |
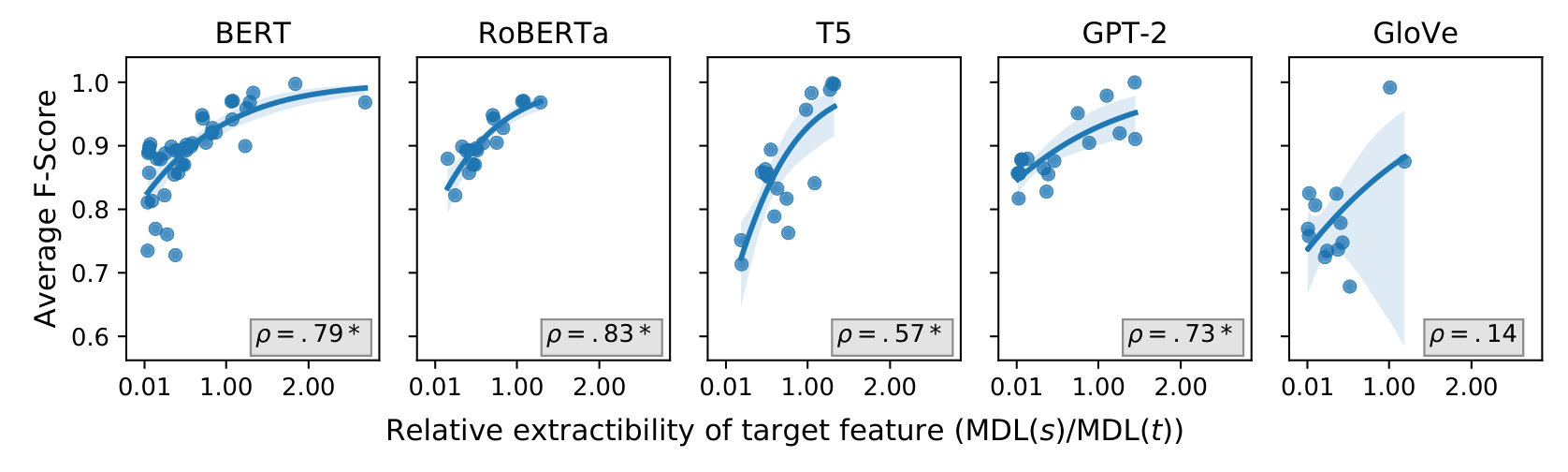
We compute Spearman's ρ between relative extractability and average test F-score across all (s, t) pairs. The correlations are strong for the pre-trained models: BERT (ρ = 0.79), RoBERTa (0.83), T5 (0.57), GPT-2 (0.73). For the GloVe-LSTM baseline, the correlation is weak (0.14)—most tasks require an s-only rate of 0.5 regardless of extractability.
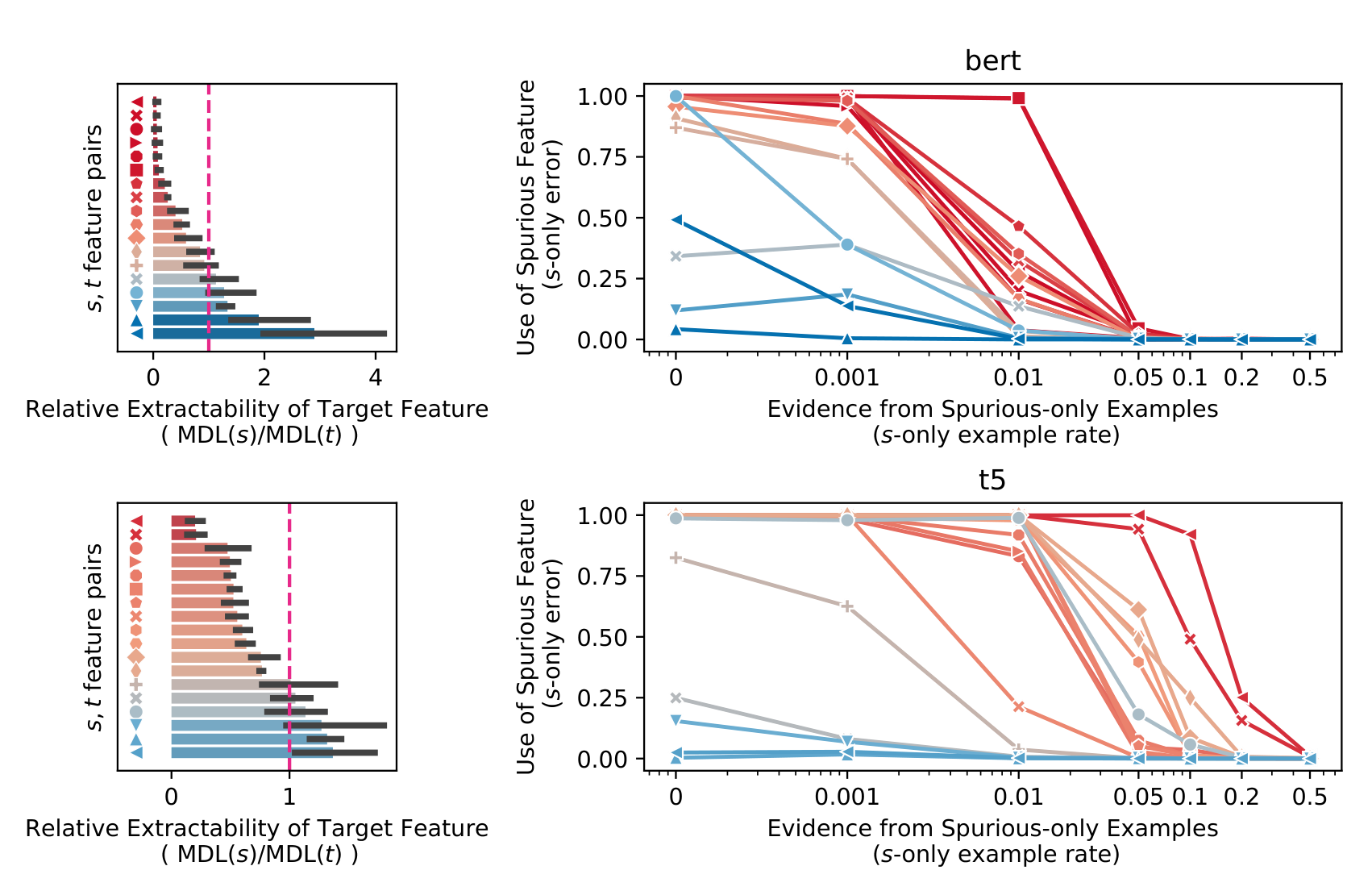
The learning curves below show this most clearly. Each line represents one (s, t) pair. For pairs where t is easier to extract than s (blue, high MDL ratio), the model solves the task correctly even when the training data provides no incentive to do so. For pairs where t is harder (red, low ratio), the model requires much more statistical evidence before it stops relying on the spurious feature. T5 generally requires more evidence than BERT. This may be because we fine-tuned T5 with a linear classification head rather than the text-only output on which it was pre-trained.
Takeaways#
Relative extractability predicts feature use. The more extractable the target feature is relative to the spurious one, the less evidence the model needs to prefer it. This holds across architectures and both synthetic and naturalistic settings.
Fine-tuning may not uncover new features. If one feature is highly extractable and another is not, the easier feature can hide the harder one—fine-tuning may not surface the needed feature even when it is technically decodable from the representation. This is a non-trivial finding: it means that if the needed feature is not already extractable-enough after pre-training, fine-tuning may not have the desired effect.
Probing classifiers as measures of inductive bias. A feature is “sufficiently” encoded if it is as available to the model as surface features of the text. If a fine-tuned model can access semantic role features as easily as lexical identity, it may need little or no explicit signal to prefer a decision rule based on the structural feature. We note that this work has not established that the relationship is causal. Intermediate task training could be used to influence extractability prior to fine-tuning; e.g., Merchant et al. (2020) suggests fine-tuning on parsing might improve the extractability of syntactic features.
Citation#
@inproceedings{lovering2021predictinginductive,
title = {Predicting Inductive Biases of Fine-tuned Models},
author = {Lovering, Charles and Jha, Rohan and Linzen, Tal and Pavlick, Ellie},
booktitle = {International Conference on Learning Representations},
year = {2021},
url = {https://openreview.net/forum?id=mNtmhaDkAr}
}