Good performance can mask flaws in deep learning systems. Evaluating systems in terms of task performance alone makes it impossible to know if they are "right for the right reasons" and difficult to predict how they will generalize. The NLP community has developed tools for this—probing classifiers that inspect internal representations, and behavioral tests that evaluate out-of-distribution generalization. We adapt both techniques to reinforcement learning, studying AlphaZero (AZ) trained to play Hex. Probing classifiers were developed for NLP by Conneau et al. and others; behavioral tests by Ettinger (2020). We apply both to a deep RL agent for the first time.
The main findings: (1) AZ's neural network encodes game concepts that humans consider important, and uses them to win games. (2) Short-term concepts are best encoded in the final layers; long-term concepts in the middle layers. (3) MCTS discovers concepts before the neural network learns to represent them. (4) AZ does not fully master negative concepts—it will waste moves on cells that cannot impact the game.
Concepts in Hex#
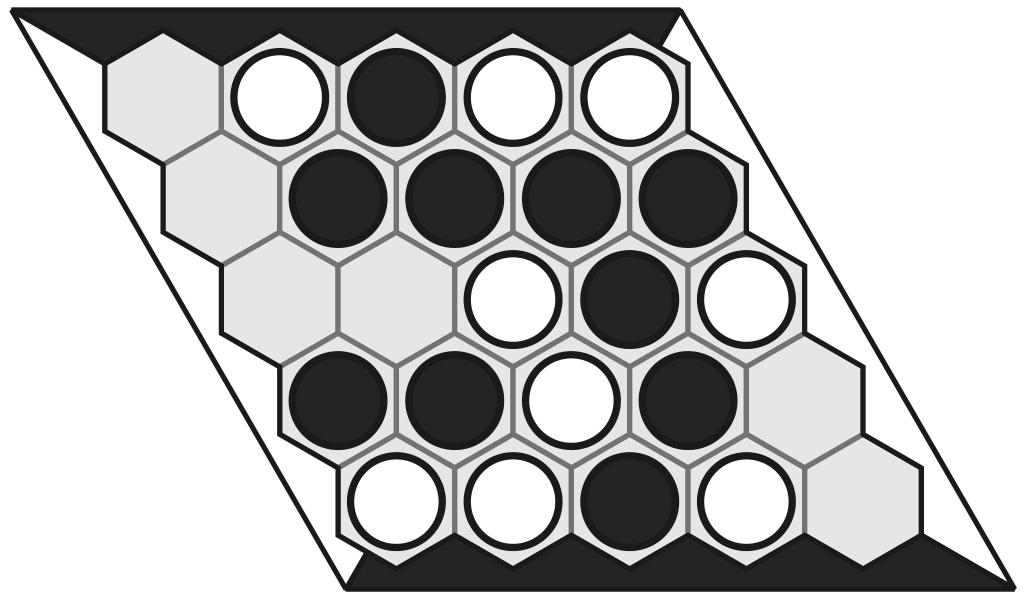
Hex is a board game where two players take turns filling cells until one builds a connecting chain across the board. Unlike Go, there are no captures. Hex cannot end in a tie, and given perfect play, the first player wins. We evaluate the top-performing agent trained by Jones (2021) on a 9×9 board: an 8-layer, 512-neuron network with 64 MCTS nodes, achieving a 92% win rate as black against MoHex.
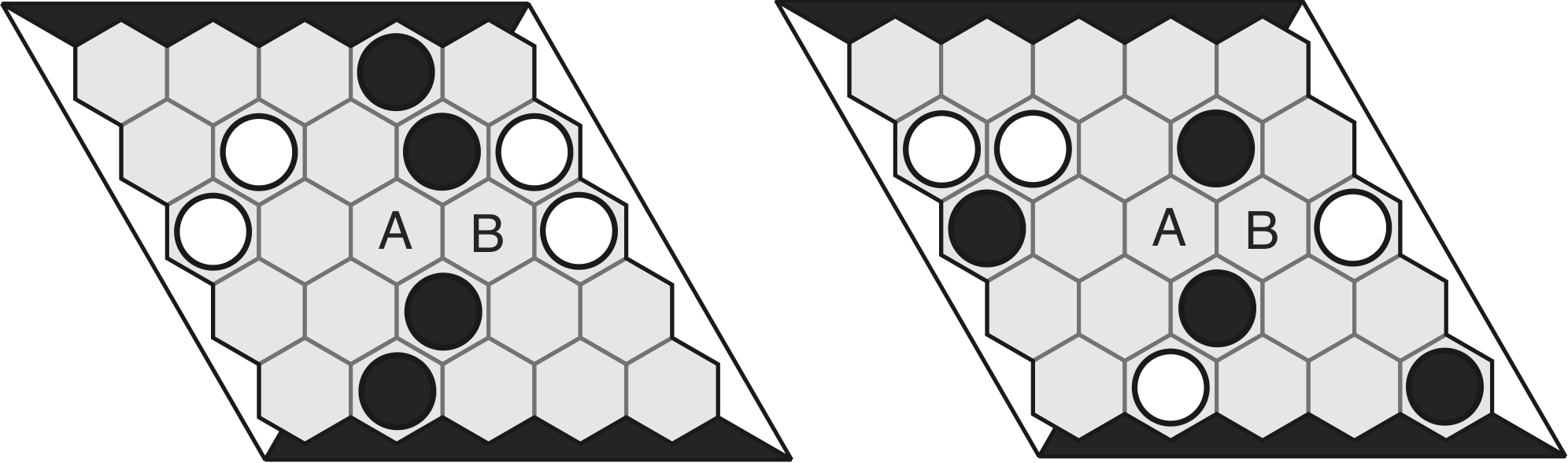
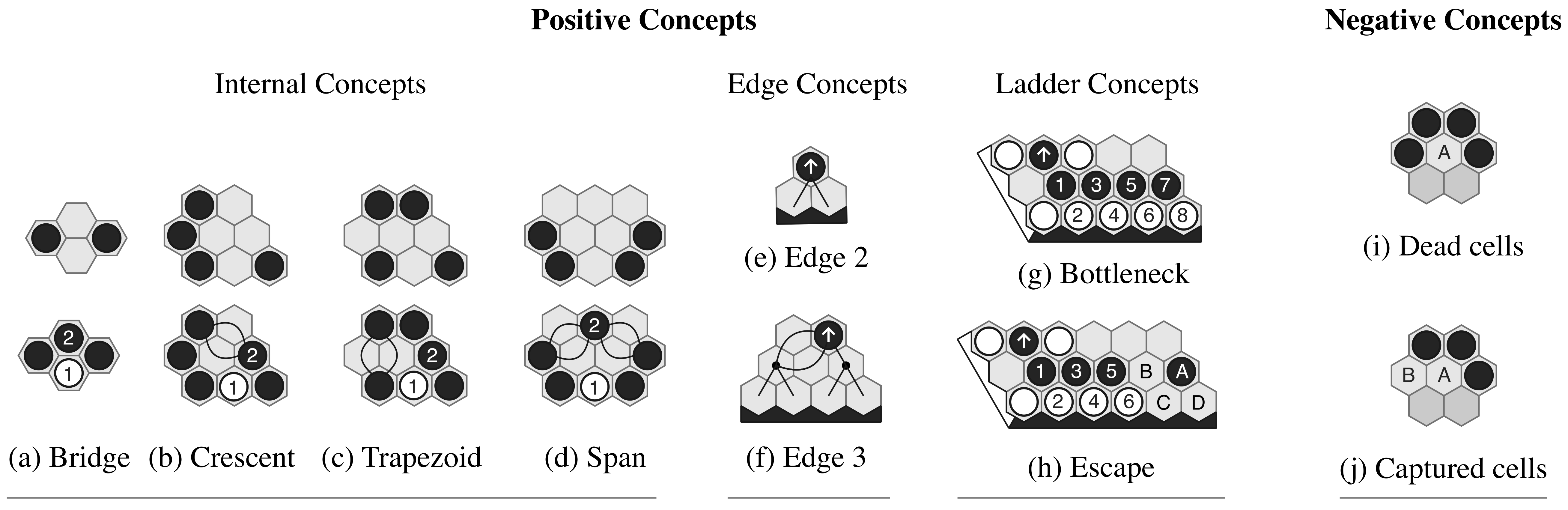
We define a concept to be short-term if its use is sufficient to win the game (typically when connected to the player's board edges), and long-term otherwise. From Seymour and King, we identify nine concepts in four categories:
- Internal concepts (bridge, crescent, trapezoid, span) — templates within the board's interior providing multiple ways to connect a player's pieces.
- Edge concepts — guarantee a connection from a single cell to a given board edge.
- Ladder concepts (bottleneck, escape) — analogous to ladders in Go. A bottleneck favors the defender; an escape allows the attacker to break through.
- Negative concepts (dead cells, captured cells) — identify which actions not to play. Dead cells cannot impact the game's outcome regardless of how they are filled. If a player can make a cell dead, that cell is captured. Both should never be filled.
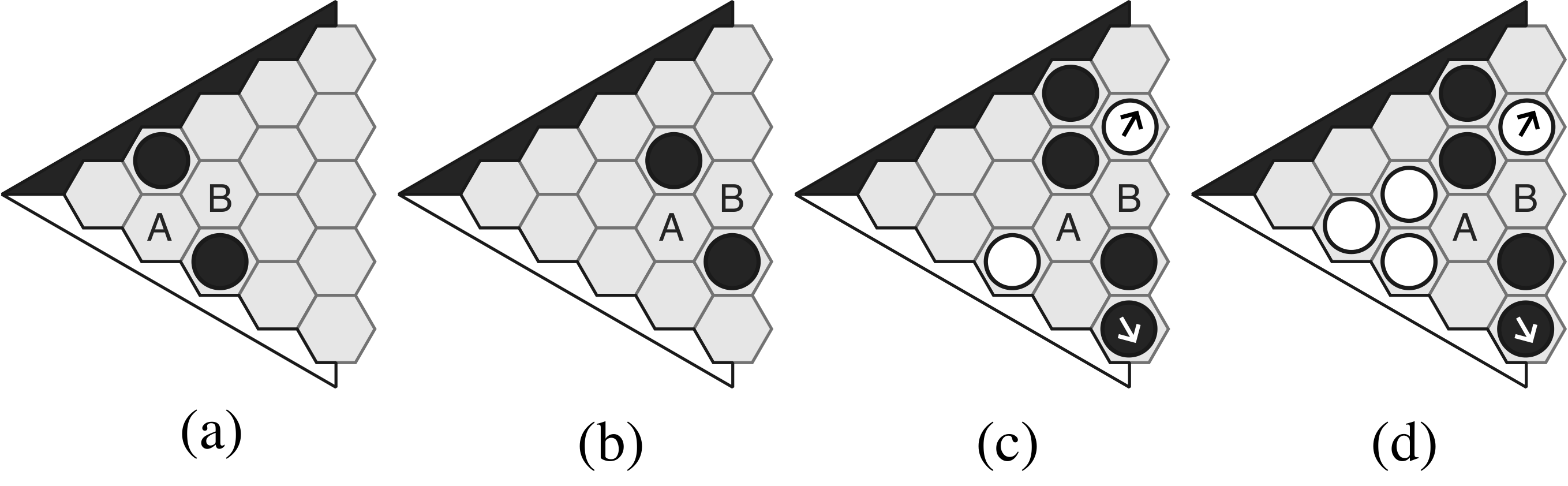
Evaluation methods#
Probing classifiers ask whether concepts are represented within the model. For each concept, we generate boards with vs. without that concept and train linear probes over AZ's internal activations to predict concept presence. We measure concept selectivity—the delta between probing accuracy and a control that shuffles cell positions so the resulting boards are meaningless in Hex. Following Hewitt and Liang (2019), we form the control by consistently remapping each cell to a random cell, preserving the information content while destroying spatial structure.
Behavioral tests ask whether the model uses concepts in gameplay. For positive concepts, we construct forced situations: if AZ plays the expected moves, AZ wins; otherwise, AZ loses. For negative concepts, we check that during a selfplay continuation, the agent does not fill dead or captured cells.
AlphaZero encodes concepts#
AZ encodes both long-term and short-term concepts with high selectivity—well above the shuffled baseline, confirming that concept-specific information is present in the network's representations, not just surface-level board features.
More interesting is where in the network these concepts live. Long-term concepts are best represented in the middle layers; short-term concepts in the final layers. This parallels findings in NLP, where syntactic information tends to peak in middle layers while task-specific features concentrate in upper layers. Concurrent work by McGrath et al. on chess found a consistent pattern: short-term concepts are better represented in higher layers than long-term concepts.
AlphaZero learns to use concepts#
AZ improves on the behavioral tests about 50% of the way through training. MCTS passing rates increase before the policy network rates—the solid line, which reports the proportion of cases where the correct action's logit is more than one standard deviation above the mean, rises earliest. This suggests "pre-conceptual" information is learned and coalesces into actionable understanding around 60% of the way through training.
AZ also improves on negative concepts, but does not reach a perfect passing rate. At the end of training, AZ still plays moves in ~25% of behavioral tests that will not impact the game. This is likely because AZ's loss function has no term to encourage winning quickly—only winning. When all value estimates are high, AZ sees little distinction between efficient and inefficient paths to victory. In one hand-analyzed example from selfplay, AZ placed higher probability on a move that extended the game rather than the move that would win immediately, because both had action values above 0.98. MoHex, by contrast, is hard-coded to connect pieces as quickly as possible.
Learning dynamics#
MCTS directly governs decision-making; the network body processes board configurations. In principle, either could discover game concepts first. We find that improvements in behavioral tests (driven by MCTS) precede improvements in probing accuracy (driven by the network). MCTS discovers concepts first; then, as the policy network is trained to match the MCTS logits, the concept representation is absorbed into the network. While behavioral tests start to improve before probing, both converge near the end of training. Exception: the ladder escape and bottleneck concepts are easy for probes to detect—perhaps because they occur along board edges and have fewer possible configurations.
Board structure#
Understanding Hex's concepts requires understanding the board's structure—which cells connect to which. AZ's feed-forward architecture does not a priori represent this. We extract cell embeddings from AZ's first layer and compute dot-product similarities. The nearest neighbors according to these scores nearly match the ground-truth hexagonal neighborhood by the 15th of 20 training checkpoints. We evaluate alignment via Normalized Discounted Cumulative Gain (NDCG). The NDCG first improves about 50% of the way through training—notably, only after the first improvements in behavioral tests, ruling out a simple "first learn the board, then learn concepts" narrative.
Citation#
See more details in our paper, Evaluation Beyond Task Performance: Analyzing Concepts in AlphaZero in Hex.
@inproceedings{lovering2022evaluation,
title = "Evaluation Beyond Task Performance:
Analyzing Concepts in {A}lpha{Z}ero
in {H}ex",
author = "Lovering, Charles and
Forde, Jessica Zosa and
Konidaris, George and
Pavlick, Ellie and
Littman, Michael L.",
booktitle = "Advances in Neural Information
Processing Systems",
year = "2022",
}